This site updates are temporary closed due to IGNOU Exam. I will come with new updates after 1st January.
Thank you,
Arafat
Read more...
This site updates are temporary closed due to IGNOU Exam. I will come with new updates after 1st January.
Thank you,
Arafat
/* A function to find length of a string */
/* length of string does not included '\0' character */
int length(char string[])
{
int i=0, len;
while(string[i] !='\0')
++i;
if(i==0)
len=0;
else
len=i;
return(len);
} /* End of function length */
And as imagination bodies forth
The forms of things to unknown, and the poet's pen
Turns them to shapes, and gives to airy nothing
A local habitation and a name.
-- Shakespeare, A Midsummer Night's Dream V(i)
Our claim that everyone programs or should learn to program might appear strange considering that, at first glance, fewer and fewer people seem to program these days. Instead, the majority of people use application packages, which don't seem to require any programming. Even programmers use ``program generators,'' packages that create programs from, say, business rules. So why should anyone learn to program?
The answer consists of two parts. First, it is indeed true that traditional forms of programming are useful for just a few people. But, programming as we the authors understand it is useful for everyone: the administrative secretary who uses spreadsheets as well as the high-tech programmer. In other words, we have a broader notion of programming in mind than the traditional one. We explain our notion in a moment. Second, we teach our idea of programming with a technology that is based on the principle of minimal intrusion. Hence our notion of programming teaches problem-analysis and problem-solving skills without imposing the overhead of traditional programming notations and tools.
To get a better understanding of modern programming, take a closer look at spreadsheets, one of today's popular application packages. A user enters formulas into a spreadsheet. The formulas describe how a cell A depends on another cell B. Then, as the user enters a number into B, the spreadsheet automatically calculates the contents of cell A. For complicated spreadsheets, a cell may depend on many other cells, not just one.
Other application packages require similar activities. Consider word processors and style sheets. A style sheet specifies how to create a (part of a) document from yet-to-be-determined words or sentences. When someone provides specific words and a style sheet, the word processor creates the document by replacing names in the style sheet with specific words. Similarly, someone who conducts a Web search may wish to specify what words to look for, what words should be next to each other, and what words should not occur in the page. In this case, the output depends on the search engine's cache of Web pages and the user's search expression.
Finally, using a program generator in many ways relies on the same skills as those necessary for application packages. A program generator creates a program in a traditional programming language, such as C++ or Java, from high-level descriptions, such as business rules or scientific laws. Such rules typically relate quantities, sales, and inventory records and thus specify computations. The other parts of the program, especially how it interacts with a user and how it stores data in the computer's disk, are generated with little or no human intervention.
All of these activities instruct some computer software to do something for us. Some use scientific notation, some may use stylized English, some use a concrete programming notation. All of them are some form of programming. The essence of these activities boils down to two concepts:
relating one quantity to another quantity, and
evaluating a relationship by substituting values for names.
Indeed, the two concepts characterize programming at the lowest level, the computer's native language, and in a modern fashionable language such as Java. A program relates its inputs to outputs; and, when a program is used for specific inputs, the evaluation substitutes concrete values for names.
No one can predict what kind of application packages will exist five or ten years from now. But application packages will continue to require some form of programming. To prepare students for these kinds of programming activities, schools can either force them to study algebra, which is the mathematical foundation of programming, or expose them to some form of programming. Using modern programming languages and environments, schools can do the latter, they can do it effectively, and they can make algebra fun.
#!/bin/sh
doindent()
{
# Do a small indent depending on how deep into the tree we are
# Depending on your environment, you may need to use
# echo " \c" instead of
# echo -en " "
j=0;
while [ "$j" -lt "$1" ]; do
echo -en " "
j=`expr $j + 1`
done
}
traverse()
{
# Traverse a directory
indent="$2"
ls "$1" | while read i
do
doindent $2
if [ -d "$1/$i" ]; then
echo "Directory: $1/$i"
# Calling this as a subshell means that when the called
# function changes directory, it will not affect our
# current working directory
traverse "$1/$i" `expr $2 + 1`
else
echo "File: $1/$i"
fi
done
}
if [ -z "$1" ]; then
traverse . 0
else
traverse "$1" 0
fi
A data structure is a group of data elements grouped together under one name. These data elements, known as members, can have different types and different lengths. Data structures are declared in C++ using the following syntax: struct structure_name { where structure_name is a name for the structure type, object_name can be a set of valid identifiers for objects that have the type of this structure. Within braces { } there is a list with the data members, each one is specified with a type and a valid identifier as its name. The first thing we have to know is that a data structure creates a new type: Once a data structure is declared, a new type with the identifier specified as structure_name is created and can be used in the rest of the program as if it was any other type. For example: We have first declared a structure type called product with two members: weight and price, each of a different fundamental type. We have then used this name of the structure type (product) to declare three objects of that type: apple, banana and melon as we would have done with any fundamental data type. Once declared, product has become a new valid type name like the fundamental ones int, char or short and from that point on we are able to declare objects (variables) of this compound new type, like we have done with apple, banana and melon. Right at the end of the struct declaration, and before the ending semicolon, we can use the optional field object_name to directly declare objects of the structure type. For example, we can also declare the structure objects apple, banana and melon at the moment we define the data structure type this way: It is important to clearly differentiate between what is the structure type name, and what is an object (variable) that has this structure type. We can instantiate many objects (i.e. variables, like apple, banana and melon) from a single structure type (product). Once we have declared our three objects of a determined structure type (apple, banana and melon) we can operate directly with their members. To do that we use a dot (.) inserted between the object name and the member name. For example, we could operate with any of these elements as if they were standard variables of their respective types: Each one of these has the data type corresponding to the member they refer to: apple.weight, banana.weight and melon.weight are of type int, while apple.price, banana.price and melon.price are of type float. Let's see a real example where you can see how a structure type can be used in the same way as fundamental types: The example shows how we can use the members of an object as regular variables. For example, the member yours.year is a valid variable of type int, and mine.title is a valid variable of type string. The objects mine and yours can also be treated as valid variables of type movies_t, for example we have passed them to the function printmovie as we would have done with regular variables. Therefore, one of the most important advantages of data structures is that we can either refer to their members individually or to the entire structure as a block with only one identifier. Data structures are a feature that can be used to represent databases, especially if we consider the possibility of building arrays of them: Here amovie is an object of structure type movies_t, and pmovie is a pointer to point to objects of structure type movies_t. So, the following code would also be valid: The value of the pointer pmovie would be assigned to a reference to the object amovie (its memory address). We will now go with another example that includes pointers, which will serve to introduce a new operator: the arrow operator (->): The previous code includes an important introduction: the arrow operator (->). This is a dereference operator that is used exclusively with pointers to objects with members. This operator serves to access a member of an object to which we have a reference. In the example we used: Which is for all purposes equivalent to: Both expressions pmovie->title and (*pmovie).title are valid and both mean that we are evaluating the member title of the data structure pointed by a pointer called pmovie. It must be clearly differentiated from: which is equivalent to: And that would access the value pointed by a hypothetical pointer member called title of the structure object pmovie (which in this case would not be a pointer). The following panel summarizes possible combinations of pointers and structure members: Structures can also be nested so that a valid element of a structure can also be in its turn another structure. After the previous declaration we could use any of the following expressions:
member_type1 member_name1;
member_type2 member_name2;
member_type3 member_name3;
.
.
} object_names;struct product {
int weight;
float price;
} ;
product apple;
product banana, melon;struct product {
int weight;
float price;
} apple, banana, melon;apple.weight
apple.price
banana.weight
banana.price
melon.weight
melon.price// example about structures
#include
#include
#include
using namespace std;
struct movies_t {
string title;
int year;
} mine, yours;
void printmovie (movies_t movie);
int main ()
{
string mystr;
mine.title = "2001 A Space Odyssey";
mine.year = 1968;
cout << "Enter title: ";
getline (cin,yours.title);
cout << "Enter year: ";
getline (cin,mystr);
stringstream(mystr) >> yours.year;
cout << "My favorite movie is:\n ";
printmovie (mine);
cout << "And yours is:\n ";
printmovie (yours);
return 0;
}
void printmovie (movies_t movie)
{
cout << class="str">" (" << class="str">")\n";
}Enter title: Alien
Enter year: 1979
My favorite movie is:
2001 A Space Odyssey (1968)
And yours is:
Alien (1979)// array of structures
#include
#include
#include
using namespace std;
#define N_MOVIES 3
struct movies_t {
string title;
int year;
} films [N_MOVIES];
void printmovie (movies_t movie);
int main ()
{
string mystr;
int n;
for (n=0; n
getline (cin,films[n].title);
cout << "Enter year: ";
getline (cin,mystr);
stringstream(mystr) >> films[n].year;
}
cout << "\nYou have entered these movies:\n";
for (n=0; n
}
void printmovie (movies_t movie)
{
cout << class="str">" (" << class="str">")\n";
}Enter title: Blade Runner
Enter year: 1982
Enter title: Matrix
Enter year: 1999
Enter title: Taxi Driver
Enter year: 1976
You have entered these movies:
Blade Runner (1982)
Matrix (1999)
Taxi Driver (1976)Pointers to structures
Like any other type, structures can be pointed by its own type of pointers:struct movies_t {
string title;
int year;
};
movies_t amovie;
movies_t * pmovie;pmovie = &amovie;
// pointers to structures
#include
#include
#include
using namespace std;
struct movies_t {
string title;
int year;
};
int main ()
{
string mystr;
movies_t amovie;
movies_t * pmovie;
pmovie = &amovie;
cout << "Enter title: ";
getline (cin, pmovie->title);
cout << "Enter year: ";
getline (cin, mystr);
(stringstream) mystr >> pmovie->year;
cout << "\nYou have entered:\n";
cout <<>title;
cout << " (" <<>year << ")\n";
return 0;
}Enter title: Invasion of the body snatchers
Enter year: 1978
You have entered:
Invasion of the body snatchers (1978)pmovie->title
(*pmovie).title
*pmovie.title
*(pmovie.title)
Expression What is evaluated Equivalent a.b Member b of object a a->b Member b of object pointed by a (*a).b *a.b Value pointed by member b of object a *(a.b) Nesting structures
struct movies_t {
string title;
int year;
};
struct friends_t {
string name;
string email;
movies_t favorite_movie;
} charlie, maria;
friends_t * pfriends = &charlie;
(where, by the way, the last two expressions refer to the same member). charlie.name
maria.favorite_movie.title
charlie.favorite_movie.year
pfriends->favorite_movie.year
One thing that you are going to notice as you learn about programming is that you tend to make a fair number of mistakes and assumptions that cause your program to either: 1) not compile, or 2) produce output that you don't expect when it executes. These problems are referred to as bugs, and the act of removing them is called debugging. About half of the time of any programmer is spent debugging.
You will have plenty of time and opportunity to create your own bugs, but to get more familiar with the possibilities let's create a few. In your program, try erasing one of the semicolons at the end of a line and try compiling the program with javac. The compiler will give you an error message. This is called a compiler error, and you have to eliminate all of them before you can execute your program. Try misspelling a function name, leaving out a "{" or eliminating one of the import lines to get used to different compiler errors. The first time you see a certain type of compiler error it can be frustrating, but by experimenting like this -- with known errors that you create on purpose -- you can get familiar with many of the common errors.
A bug, also known as an execution (or run-time) error, occurs when the program compiles fine and runs, but then does not produce the output you planned on it producing. For example, this code produces a red rectangle with two diagonal lines across it:
g.setColor(Color.red);
g.fillRect(0, 0, 200, 200);
g.setColor(Color.black);
g.drawLine(0, 0, 200, 200);
g.drawLine(200, 0, 0, 200);
The following code, on the other hand, produces just the red rectangle (which covers over the two lines):
g.setColor(Color.black);
g.drawLine(0, 0, 200, 200);
g.drawLine(200, 0, 0, 200);
g.setColor(Color.red);
g.fillRect(0, 0, 200, 200);
The code is almost exactly the same but looks completely different when it executes. If you are expecting to see two diagonal lines, then the code in the second case contains a bug.
Here's another example:
g.drawLine(0, 0, 200, 200);
g.drawRect(0, 0, 200, 200);
g.drawLine(200, 0, 0, 200);
This code produces a black outlined box and two diagonals. This next piece of code produces only one diagonal:
g.drawLine(0, 0, 200, 200);
g.drawRect(0, 0, 200, 200);
g.drawLine(0, 200, 0, 200);
Again, if you expected to see two diagonals, then the second piece of code contains a bug (look at the second piece of code until you understand what went wrong). This sort of bug can take a long time to find because it is subtle.
You will have plenty of time to practice finding your own bugs. The average programmer spends about half of his or her time tracking down, finding and eliminating bugs. Try not to get frustrated when they occur -- they are a normal part of programming life.
Looking for a premium quality WordPress theme? But, don’t want to spend a dime? Don’t waste your time turning the whole world wide web upside down! Just take a look at WordPress Max theme by Gabfire web design. From AJAX control panel for theme options to fully optimized magazine/newspaper style front page, all features in this theme are premium. And the good thing is that it is available for free download.

With WordPress Max theme, in the front page of your WordPress powered blog, you will be able to display featured posts, latest posts and categorized posts along with auto-cropped and resized thumbnails. Then there is a carousel in the middle for displaying posts by large pictures. In the sidebar you can display most viewed posts, most commented posts, tags etc with the help of AJAX tabs. There is also a video panel to play latest videos on sidebar. Then there are 4 advertising positions that can be controlled directly from the theme control panel. With so many features and options available on this theme, you can easily create a content rich, news blog, powered by WordPress. Take a look at the demo and download it today.
Overview of WordPress Max theme features:

Wanna know the secret of virus. How it's deal with your machine. Then I just try to reveal it. Actually I spend some time over net for a research on virus and I now coming to serve you a small details on it.
Strange as it may sound, the computer virus is something of an Information Age marvel. On one hand, viruses show us how vulnerable we are -- a properly engineered virus can have a devastating effect, disrupting productivity and doing billions of dollars in damages. On the other hand, they show us how sophisticated and interconnected human beings have become. For example, experts estimate that the Mydoom worm infected approximately a quarter-million computers in a single day in January 2004. Back in March 1999, the Melissa virus was so powerful that it forced Microsoft and a number of other very large companies to completely turn off their e-mail systems until the virus could be contained. The ILOVEYOU virus in 2000 had a similarly devastating effect. In January 2007, a worm called Storm appeared -- by October, experts believed up to 50 million computers were infected. That's pretty impressive when you consider that many viruses are incredibly simple.
When you listen to the news, you hear about many different forms of electronic infection. The most common are:
Stay tuned will come with much more information about virus soon.

Computer languages have undergone dramatic evolution since the first electronic computers were built to assist in telemetry calculations during World War II. Early on, programmers worked with the most primitive computer instructions: machine language. These instructions were represented by long strings of ones and zeroes. Soon, assemblers were invented to map machine instructions to human-readable and -manageable mnemonics, such as ADD and MOV. In time, higher-level languages evolved, such as BASIC and COBOL. These languages let people work with something approximating words and sentences, such as Let I = 100. These instructions were translated back into machine language by interpreters and compilers. An interpreter translates a program as it reads it, turning the program instructions, or code, directly into actions. A compiler translates the code into an intermediary form. This step is called compiling, and produces an object file. The compiler then invokes a linker, which turns the object file into an executable program. Because interpreters read the code as it is written and execute the code on the spot, interpreters are easy for the programmer to work with. Compilers, however, introduce the extra steps of compiling and linking the code, which is inconvenient. Compilers produce a program that is very fast each time it is run. However, the time-consuming task of translating the source code into machine language has already been accomplished. Another advantage of many compiled languages like C++ is that you can distribute the executable program to people who don't have the compiler. With an interpretive language, you must have the language to run the program.
<
 No more white look now. Google now in a race and continuously introducing new feature. From today you can say bye bye to your gmail white-blue-black look. From today you are in the new world of color in gmail. Just go to your setting and find themes tab:-
No more white look now. Google now in a race and continuously introducing new feature. From today you can say bye bye to your gmail white-blue-black look. From today you are in the new world of color in gmail. Just go to your setting and find themes tab:-

 So, go and check the new world of color.
So, go and check the new world of color.The solution is :
All computers have memory, also known as RAM (random access memory). For example, your computer might have 16 or 32 or 64 megabytes of RAM installed right now. RAM holds the programs that your computer is currently running along with the data they are currently manipulating (their variables and data structures). Memory can be thought of simply as an array of bytes. In this array, every memory location has its own address -- the address of the first byte is 0, followed by 1, 2, 3, and so on. Memory addresses act just like the indexes of a normal array. The computer can access any address in memory at any time (hence the name "random access memory"). It can also group bytes together as it needs to to form larger variables, arrays, and structures. For example, a floating point variable consumes 4 contiguous bytes in memory. You might make the following global declaration in a program:
float f;
This statement says, "Declare a location named f that can hold one floating point value." When the program runs, the computer reserves space for the variable f somewhere in memory. That location has a fixed address in the memory space, like this:

While you think of the variable f, the computer thinks of a specific address in memory (for example, 248,440). Therefore, when you create a statement like this:
f = 3.14;
The compiler might translate that into, "Load the value 3.14 into memory location 248,440." The computer is always thinking of memory in terms of addresses and values at those addresses.
There are, by the way, several interesting side effects to the way your computer treats memory. For example, say that you include the following code in one of your programs:
int i, s[4], t[4], u=0;
for (i=0; i<=4; i++)
{
s[i] = i;
t[i] =i;
}
printf("s:t\n");
for (i=0; i<=4; i++)
printf("%d:%d\n", s[i], t[i]);
printf("u = %d\n", u);
The output that you see from the program will probably look like this:
s:t
1:5
2:2
3:3
4:4
5:5
u = 5
Why are t[0] and u incorrect? If you look carefully at the code, you can see that the for loops are writing one element past the end of each array. In memory, the arrays are placed adjacent to one another, as shown here:
 |
Therefore, when you try to write to s[4], which does not exist, the system writes into t[0] instead because t[0] is where s[4] ought to be. When you write into t[4], you are really writing into u. As far as the computer is concerned, s[4] is simply an address, and it can write into it. As you can see however, even though the computer executes the program, it is not correct or valid. The program corrupts the array t in the process of running. If you execute the following statement, more severe consequences result:
s[1000000] = 5;
The location s[1000000] is more than likely outside of your program's memory space. In other words, you are writing into memory that your program does not own. On a system with protected memory spaces (UNIX, Windows 98/NT), this sort of statement will cause the system to terminate execution of the program. On other systems (Windows 3.1, the Mac), however, the system is not aware of what you are doing. You end up damaging the code or variables in another application. The effect of the violation can range from nothing at all to a complete system crash. In memory, i, s, t and u are all placed next to one another at specific addresses. Therefore, if you write past the boundaries of a variable, the computer will do what you say but it will end up corrupting another memory location.
Because C and C++ do not perform any sort of range checking when you access an element of an array, it is essential that you, as a programmer, pay careful attention to array ranges yourself and keep within the array's appropriate boundaries. Unintentionally reading or writing outside of array boundaries always leads to faulty program behavior.
As another example, try the following:
#include
int main()
{
int i,j;
int *p; /* a pointer to an integer */
printf("%d %d\n", p, &i);
p = &i;
printf("%d %d\n", p, &i);
return 0;
}
This code tells the compiler to print out the address held in p, along with the address of i. The variable p starts off with some crazy value or with 0. The address of i is generally a large value. For example, when I ran this code, I received the following output:
0 2147478276
2147478276 2147478276
which means that the address of i is 2147478276. Once the statement p = &i; has been executed, p contains the address of i. Try this as well:
#include
void main()
{
int *p; /* a pointer to an integer */
printf("%d\n",*p);
}
This code tells the compiler to print the value that p points to. However, p has not been initialized yet; it contains the address 0 or some random address. In most cases, a segmentation fault (or some other run-time error) results, which means that you have used a pointer that points to an invalid area of memory. Almost always, an uninitialized pointer or a bad pointer address is the cause of segmentation faults.
Having said all of this, we can now look at pointers in a whole new light. Take this program, for example:
#include
int main()
{
int i;
int *p; /* a pointer to an integer */
p = &i;
*p=5;
printf("%d %d\n", i, *p);
return 0;
}
Here is what's happening:

The variable i consumes 4 bytes of memory. The pointer p also consumes 4 bytes (on most machines in use today, a pointer consumes 4 bytes of memory. Memory addresses are 32-bits long on most CPUs today, although there is a increasing trend toward 64-bit addressing). The location of i has a specific address, in this case 248,440. The pointer p holds that address once you say p = &i;. The variables *p and i are therefore equivalent.
The pointer p literally holds the address of i. When you say something like this in a program:
printf("%d", p);
what comes out is the actual address of the variable i.
![]()
If you are trying to make some game or anything related to graphics then this is your first choice. This is free and almost compete to most paid soft of similar kind. So download now. Click here to download.
Microsoft's free download, which the company is calling "Morro," is designed to defend consumers' PCs against malware, such as viruses, spyware and Trojans. Following Microsoft's announcement, Symantec and McAfee stocks took a nosedive Wednesday over concerns that the software giant would take a significant portion of their market share in the PC security space. Symantec shares fell 9.44 percent to $11.23, while McAfee's dropped 6.62 percent to $26.68. However, Microsoft also fell 6 percent at $18.45. So, lets see what going to happen in next 30 days.
The Microsoft hunt for market continue. They now trying to compete all major security software provider like Symantec or McAfee.
To understand pointers, it helps to compare them to normal variables.
A "normal variable" is a location in memory that can hold a value. For example, when you declare a variable i as an integer, four bytes of memory are set aside for it. In your program, you refer to that location in memory by the name i. At the machine level that location has a memory address. The four bytes at that address are known to you, the programmer, as i, and the four bytes can hold one integer value.
A pointer is different. A pointer is a variable that points to another variable. This means that a pointer holds the memory address of another variable. Put another way, the pointer does not hold a value in the traditional sense; instead, it holds the address of another variable. A pointer "points to" that other variable by holding a copy of its address.
Because a pointer holds an address rather than a value, it has two parts. The pointer itself holds the address. That address points to a value. There is the pointer and the value pointed to. This fact can be a little confusing until you get comfortable with it, but once you get comfortable it becomes extremely powerful.
The following example code shows a typical pointer:
#include
int main()
{
int i,j;
int *p; /* a pointer to an integer */
p = &i;
*p=5;
j=i;
printf("%d %d %d\n", i, j, *p);
return 0;
}
The first declaration in this program declares two normal integer variables named i and j. The line int *p declares a pointer named p. This line asks the compiler to declare a variable p that is a pointer to an integer. The * indicates that a pointer is being declared rather than a normal variable. You can create a pointer to anything: a float, a structure, a char, and so on. Just use a * to indicate that you want a pointer rather than a normal variable.
The line p = &i; will definitely be new to you. In C, & is called the address operator. The expression &i means, "The memory address of the variable i." Thus, the expression p = &i; means, "Assign to p the address of i." Once you execute this statement, p "points to" i. Before you do so, p contains a random, unknown address, and its use will likely cause a segmentation fault or similar program crash.
One good way to visualize what is happening is to draw a picture. After i, j and p are declared, the world looks like this:

In this drawing the three variables i, j and p have been declared, but none of the three has been initialized. The two integer variables are therefore drawn as boxes containing question marks -- they could contain any value at this point in the program's execution. The pointer is drawn as a circle to distinguish it from a normal variable that holds a value, and the random arrows indicate that it can be pointing anywhere at this moment.
After the line p = &I;, p is initialized and it points to i, like this:

Once p points to i, the memory location i has two names. It is still known as i, but now it is known as *p as well. This is how C talks about the two parts of a pointer variable: p is the location holding the address, while *p is the location pointed to by that address. Therefore *p=5 means that the location pointed to by p should be set to 5, like this:

Because the location *p is also i, i also takes on the value 5. Consequently, j=i; sets j to 5, and the printf statement produces 5 5 5.
The main feature of a pointer is its two-part nature. The pointer itself holds an address. The pointer also points to a value of a specific type - the value at the address the point holds. The pointer itself, in this case, is p. The value pointed to is *p.
Okay, you get it: you should be posting on a forum. Now what?
1. Build Your Profile
When you register for a forum, you should fill in as much information as possible. Most forums have a page for your user details. People visit this page when they want to know more about you or send you a private message. Describe what you do and what your web site is about.
Avatars are an important part of your profile. Because of the volume of text on a forum page, avatars are the way people identify the poster. Make sure your avatar is unique and recognizable at a glance—you want to make sure people associate you with your ideas. And if you use an avatar on multiple forums and social networks, use the same one.
Most importantly, write a strong signature. This is the text that will appear at the bottom of every post you write, so put some thought into it. Like the signature of an email, your forum signature says who you are. Use your signature to link to your website.
2. Follow the Rules
Read the rules of the forum carefully, and follow them. Take the time to read through the discussions to get an idea of how people converse. There are implicit social norms that you must be mindful of.
If you follow my ten rules, you probably won’t violate any forum rules, but don’t take any chances.
3. Start by Responding
Forums are about conversations and communities. One person starts a thread, either with a question or a comment, then others respond, either with answers or their own comments.
People give advice free of charge in forums, but at the cost of their time and energy. They rightfully expect that the favor will be returned, so they shun people who take without anything to give.
It may not be your intention to be a leach on the community, but participants are wary of newcomers automatically. Take the time to respond to others before asking anything yourself. Post in other user’s threads before you start your own.
Most forums show the number of posts of the author next to every comment. Make 50 posts before you start your own thread. You might have an important question for the community, but it’s best to establish some social capital first. Otherwise, your question may be ignored.
4. Contribute Your Expertise
Don’t hold back. If you have an expert opinion, demonstrate it. Don’t give a half-baked response telling the member they can learn more if they follow the link to your page. Contribute highly relevant information immediately and in abundance. You don’t have to qualify your expertise unless it’s asked for. That’s what your profile is for.
5. Don’t Be a “Me Too” Poster
If someone has already said it, don’t bother repeating it. All you’re doing is wasting your energy and other people’s time. That’s not to say you shouldn’t state your agreement with someone else, but make sure you provide additional support to their argument.
In the event another poster disagrees with a thread you support, use the opportunity to contribute a new angle to the argument, using your own expertise.
6. Don’t Self-promote
Even if it’s allowed within the rules of the forum, don’t post about your own web site and products, unless it’s in direct response to a request for information. If you want to promote yourself, your signature is the place to do it.
On the flip side, tell people about great products you aren’t affiliated with. Sharing information is why forums exist.
7. Explain Yourself, but Be Brief
Don’t assume people have the same level of knowledge on a subject as you, but don’t imagine that they have the time or inclination to be either. Make your point straight away, then back it up with support. People who are interested in your initial thought will read more; those who aren’t will skip your comment and move on to the next thread.
Make sure you’re writing for the Web. Keep sentences and paragraphs short, with plenty of white space. Less is more.
8. If You’re Wrong, Say So
Forum discussions often hinge upon opinion, so nothing is more attention-grabbing than a poster on an internet forum admitting that they were wrong!
If you’re in the heat of a discussion, and someone persuades you to change your mind, say so. It’s a pretty big deal, and furthermore, you should thank that person.
Remember that forums aren’t soapboxes— they’re platforms for conversations and an opportunity to network.
9. Write Intelligently and Correctly
You don’t have to carefully revise and sculpt every forum post, but you should proof everything once. Consider using the spell-check if you’re not an impeccable speller.
Although most forums don’t set specific rules on grammar and punctuation, you should give thought to this: everything you say, every single post, every nugget of wisdom, is a representation of your personal brand. Writing like an intelligent adult is the equivalent of maintaining proper hygiene and a presentable appearance in the workplace; if you don’t pay any attention to it, it can undermine everything else you do.
However, be aware that the Internet is a global phenomenon, and some of the people you interact with will be non-native English speakers. You don’t need to point out any mistakes your fellow posters make.
10. Negativity is a No-no
It goes without saying, just because you have a degree of anonymity, communicating from the safety of your work desk, doesn’t mean you can harass other posters. This is especially the case when you’re trying to build an online reputation and attract users to your site. Forums posts may fall off the main page, but they never go away.
If someone disagrees with you, respond with a thoughtful rebuttal, or thank them for their opinion—for example, “It’s always interesting to hear a different take.” If someone attacks you, either thank them as if they’d simply disagreed, or ignore them entirely.
All forums have trolls—people who aggressively harass you just for their own entertainment. The worst thing you can do is engage with them.
Let’s now take a look at a recent post I made on the SitePoint forums that demonstrates these rules in practice. I came across a pricing question in the Promotional Techniques forum that I thought I could answer.
Luc Deacu wrote:
Hello everyone,
Soon we’ll be launching a program that we’ve been working on for the past year, which was originally going to be priced at $25 per month or more. In the last week or so, however, I’ve given it some further thought and have decided to release it free-of-charge.
I came to this decision because I wanted to give it a test run, to see if the public liked it as much as we expect them to. We thought that it would be a better move, ultimately, if we created a premium version—in addition to the current one—and pricing just that version instead.
Do you agree with our decision? What are some of the pros and cons of handling it this way? Have you ever done it before, and if so, how did it go?
Thanks in advance,
Luc
I responded:
Consider pricing it at $25, but offering a discount code to all the places you are promoting your product.
For instance “We’ve got great new product X, which only costs $25. But we’re running a promotion, and right now you can use discount code GIMMENOW to take advantage of our 100% Off Coupon (Yes, that means FREE)”
This does a few things. First, it makes your offer temporary, so people will know they have to act now to take advantage. Second, it favors the people you’re offering the code to, and they’ll respond to your generosity. Third, whoever you ask to promote it for you will feel good about doing so, because they’re doing something nice for their audience.
Here is a screenshot:
Note my recognizable avatar and the link to my blog in the signature. Luc appreciated the advice and decided to try my idea. I hope he’ll let us know how it went.
In this article I presented 10 rules for boosting traffic to your web site that hinged upon your involvement in an online forum. My experience is that, by following these rules, your web site will see an increase in high quality traffic. However, they’re also a good list of rules to follow when interacting online anyway—be polite, helpful, respectful and generous, and everybody wins.
ROBO is a new and very simple educational programming language that will familiarize you with the basics of computer science by programming your own robot. In addition to an introduction into popular programming techniques, you will also gain insight into areas such as robotics and artificial intelligence. Download this freeware here
Download this freeware here
This file will change the Icons and names of the Recycle Bin, my computer, and Network Neighborhood for you. It will even restore the defaults when you want. FREEWARE. Note you should delete the file ShellIconCache after making the changes. This file will rebuild itself after rebooting. FREEWARE
Grab this freeware here
Imagine that you would like to create a text editor -- a program that lets you edit normal ASCII text files, like "vi" on UNIX or "Notepad" on Windows. A text editor is a fairly common thing for someone to create because, if you think about it, a text editor is probably a programmer's most commonly used piece of software. The text editor is a programmer's intimate link to the computer -- it is where you enter all of your thoughts and then manipulate them. Obviously, with anything you use that often and work with that closely, you want it to be just right. Therefore many programmers create their own editors and customize them to suit their individual working styles and preferences. So one day you sit down to begin working on your editor. After thinking about the features you want, you begin to think about the "data structure" for your editor. That is, you begin thinking about how you will store the document you are editing in memory so that you can manipulate it in your program. What you need is a way to store the information you are entering in a form that can be manipulated quickly and easily. You believe that one way to do that is to organize the data on the basis of lines of characters. Given what we have discussed so far, the only thing you have at your disposal at this point is an array. You think, "Well, a typical line is 80 characters long, and a typical file is no more than 1,000 lines long." You therefore declare a two-dimensional array, like this: This declaration requests an array of 1,000 80-character lines. This array has a total size of 80,000 characters. As you think about your editor and its data structure some more, however, you might realize three things: That doesn't seem like an unreasonable thing, until you pull out your calculator, multiply 50,000 by 1,000 by 10 and realize the array contains 500 million characters! Most computers today are going to have a problem with an array that size. They simply do not have the RAM, or even the virtual memory space, to support an array that large. If users were to try to run three or four copies of this program simultaneously on even the largest multi-user system, it would put a severe strain on the facilities. Even if the computer would accept a request for such a large array, you can see that it is an extravagant waste of space. It seems strange to declare a 500 million character array when, in the vast majority of cases, you will run this editor to look at 100 line files that consume at most 4,000 or 5,000 bytes. The problem with an array is the fact that you have to declare it to have its maximum size in every dimension from the beginning. Those maximum sizes often multiply together to form very large numbers. Also, if you happen to need to be able to edit an odd file with a 2,000 character line in it, you are out of luck. There is really no way for you to predict and handle the maximum line length of a text file, because, technically, that number is infinite. Pointers are designed to solve this problem. With pointers, you can create dynamic data structures. Instead of declaring your worst-case memory consumption up-front in an array, you instead allocate memory from the heap while the program is running. That way you can use the exact amount of memory a document needs, with no waste. In addition, when you close a document you can return the memory to the heap so that other parts of the program can use it. With pointers, memory can be recycled while the program is running.
char doc[1000][80];
Let's say you set a maximum of 10 open files at once, a maximum line length of 1,000 characters and a maximum file size of 50,000 lines. Your declaration now looks like this: char doc[50000][1000][10];
Visitors to your web site by way of forums are worth two to six times the average visitor. Why? Well, I’ve found that forum visitors are proactive information seekers, community-minded participants, and engaged users. They do more everything.
The evidence: traffic to my own blog.
In this article, I’m going to show you why you should use forums to drive traffic to your web site, and then give you ten rules for how to go about doing so. As an example, I’ll discuss a forum that I participate in that is SitePoint Forums.
I use this forum for three reasons:
Although the SitePoint forum does not deliver thousands of visitors to my blog each month, the forum traffic is of the highest quality. They read more, participate more, and come back for more.
Here is some of my analytics data from the past two months. We’ll compare average metrics for visitors coming from the SitePoint forum to the averages for all site visitors.
Note: This is a useful exercise for you to conduct with your own site. Once you’ve established which sites are referring the most high quality traffic, redouble your efforts at those sites.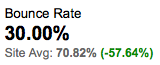
Normally, 71% of my visitors leave without viewing a second page (they were expecting someone taller). Only 30% of my visitors from the forum leave immediately.
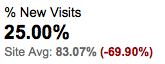
83% of my visitors are new to the site. But when they come from the forum, 75% are returning for a second time (or more).

The average visitor only looks at 2.5 pages on my site. Visitors from the forum look at over 9.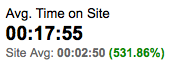
When someone from the forums comes to my web site, they spend an average of 18 minutes on my site. That’s 532% of the average for all of my visitors, who visit for 3 minutes on average.
These numbers demonstrate that visitors from SitePoint are more engaged with my site, more interested in what I have to say, and more likely to return. The average visitor from the forum appears to be worth 2 to 6 times an average visitor.
This is important whether your visitor’s intended action is to read your content, or to buy your product. Engaged visitors are more easily reached with your message.
Forum visitors are interested in self-education and connecting with like-minded people. They’ve already sampled some of your writing, since they followed a link associated with something you said in the forum. And by clicking on that link, these visitors are saying, “tell me more!”
Even if it seems impossible to drive forum traffic to your site, you should participate. Forums are a great place to learn about the topics that interest you, and you can also use them to build networks of contacts—, professional and personal.
This inherent value in forums is exactly why they produce quality visitors. People who click are already qualified visitors.
It’s important that my web site isn’t a rehash of the information forum visitors already know. Most SitePoint readers are web designers and developers first, marketers second, so I have something to offer them.
Remember, forums are for driving human traffic to your site, not for boosting your search engine rankings. Some SEO bloggers suggest posting on forums as a way to build links pointing to your domain. Creating a link in your signature means that every post you make on the forum will refer to your site.
However, these links aren’t as useful for SEO as you might expect. Forum threads are rarely considered authoritative by engines, since they’re not used to link to. Forum pages also have hundreds of outbound links, well over the number recommended by the official Google guidelines. Whatever authority the page has is diminished by the abundance of links.
But make no mistake: a signature link is best practice. It’s a way of promoting yourself in a valuable way without being brash. People reading your comments need a way to learn more about who you are and what you do, so a link to your site is value-added content.
Signature links aren’t for search engines, they’re for people. Any SEO benefit is peripheral.
What I’m talking about here is the code required to understand the rules of a game, which can then evaluate situations and tactics in order to try to beat you at that game. Complicated stuff.
To illustrate, I’m going to look at a project I’ve been developing on the side for a little while. By “little while” I mean three years, the majority of which was spent at a plateau where the game theoretically worked, but was too intense to use … until I thought of this approach. The game is a competitive puzzle based around color- and shape-matching.

To summarize: you make your way across the board by adjacent shape- and color-matching. For example, if you start on, say, a green triangle—then you can move to any other triangle, or any other green shape. Your objective is to reach the crystal in the middle, then take it to the other side of the board, while your opponent tries to do the same. You can also steal the crystal from your opponent.
So, we have logical rules determining movement and we can also see tactics emerging. For example, to avoid having your opponent reach the crystal, or stealing it from you—you might select a move that blocks them, or try to finish at a place they can’t reach.
The work of the computer is to find the best move for any given situation, so let’s have a look at that process in summary pseudo-code:
function compute()
{
var move = null;
move = tactic1();
if(!move) { move = tactic2(); }
if(!move) { move = tactic3(); }
if(move)
{
doit();
}
else
{
pass();
}
}
We evaluate a tactic, and if that gives us a good move then we’re done; otherwise we evaluate another tactic, and so on, until we either have a move, or conclude that there isn’t one and we have to pass.
Each of those tactic functions runs an expensive process, as it has to evaluate every position on the board, as well as potential future positions, possibly many times each in light of various factors. The example only has three tactics, but in the real game there are dozens of different possibilities, each one expensive to evaluate.
Any one of those evaluations individually is fine, but all of them together, run consecutively, make for an overly intense process that freezes the browser.
So what I did was split the main code into discreet tasks, each of which is selected with a switch statement, and iterated over using an asynchronous timer. The logic of this is not a million miles away from those Choose Your Own Adventure books I used to have as a kid, where each task concludes with a choice of further tasks, all in real time, until we reach the end:
function compute()
{
var move = null;
var busy = false, task = 'init';
var processor = setInterval(function()
{
if(!busy)
{
switch(task)
{
case 'init' :
move = tactic1();
if(move) { task = 'doit'; }
else { task = 'tactic2'; }
busy = false;
break;
case 'tactic2' :
move = tactic2();
if(move) { task = 'doit'; }
else { task = 'tactic3'; }
busy = false;
break;
case 'tactic3' :
move = tactic3();
if(move) { task = 'doit'; }
else { task = 'pass'; }
busy = false;
break;
case 'doit' :
doit();
task = 'final';
busy = false;
break;
case 'pass' :
pass();
task = 'final';
busy = false;
break;
case 'final' :
clearInterval(processor);
busy = false;
break;
}
}
}, 100);
}
This code is significantly more verbose than the original, so if reducing code size were the only imperative, this would clearly not be the way to go.
But what we’re trying to do here is create an execution environment with no ceiling, that is, a process that doesn’t have an upper limit in terms of complexity and length; and that’s what we’ve done.
This pattern can be extended indefinitely, with hundreds or even thousands of tasks. It might take a long time to run, but run it will, and as long as each individual task is not too intense, it will run without killing the browser.
The strength of this approach is also its major weakness: since the inner function is asynchronous, we cannot return a value from the outer function. So, for example, we cannot do this (or rather, we can, but there would be no point):
function checksomething()
{
var okay = false;
var i = 0, limit = 100, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
if(condition)
{
okay = true;
}
if(++i == limit)
{
clearInterval(processor);
}
busy = false;
}
}, 100);
return okay;
}
That checksomething() function will always return false because the inner function is asynchronous. The outer function will return before the first iteration of the inner function has even happened!
This next example is similarly pointless:
if(++i == limit)
{
clearInterval(processor);
return okay;
}
We’re out of the scope of the outer function, therefore we’re unable to return from it; that return value disappears uselessly into the ether.
What we can do here is take a leaf out of Ajax coding techniques, and use a callback function (which in this example I’m calling “oncomplete”):
function checksomething(oncomplete)
{
var okay = false;
var i = 0, limit = 100, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
if(condition)
{
okay = true;
}
if(++i == limit)
{
clearInterval(processor);
if(typeof oncomplete == 'function')
{
oncomplete(okay);
}
}
busy = false;
}
}, 100);
}
So when we call checksomething(), we pass an anonymous function as its argument, and that function is called with the final value when the job is complete:
checksomething(function(result)
{
alert(result);
});
Elegant? No. But robustly functional? Yes. And that’s the point. Using this technique, we can write scripts that would otherwise be impossible.
With this technique in our kit, we now have a means for tackling JavaScript projects that were previously way out of the realm of possibility. The game I developed this pattern for has fairly simple logic, and hence a fairly simple brain, but it was still too much for conventional iteration; and there are plenty of other games out there that need a good deal more clout!
My next plan is to use this technique to implement a JavaScript Chess engine. Chess has a huge range of possible scenarios and tactics, leading to decisions that could take an extremely long time to calculate, far longer than would have been feasible without this technique. Intense computation is required to create even the most basic thinking machine, and I confess to being quite excited about the possibilities.
If we can pull off tricks like this, who’s to say what’s possible? Natural language processing, heuristics … perhaps we have the building blocks to develop Artificial Intelligence in JavaScript!
Many people want to earn money with forum posting. There are several in the list. I here listed 6 of them with small review.
HostBidder: A nice site with lot of reputation. Online nearly 2 years and still don't produce any complain on there service. The minimum payout is $15. You can earn 1 to 10 point for each post. You can exchange 2000 point with $15.
MakeMoneyKingdom : This is a growing forum which paid 3cent for post and 4cent for new thread. $7 minimum payout. Also have referral earning.
MortgaGefit : The minimum payout is $10. You can earn money by posting on forum, submitting a new story or sharing a finance video.
CreditMagic : $50 minimum payout. You can earn point through forum posting. 1point=1cent.
Webmasters-Forums : You can make money just for posting on this forum. Every discussions on this community gives you more money. $2 minimum payout. 2$ for 500 Points.
MkpitStop : $10 minimum payout. Pay you for each character in forum.
Paid forum posting is currently one of my favorite ways to earn money online. The concept is very simple. There are new forums opening every day, and webmasters need some help to get them going, or perhaps they want to add some life to an already existing forum, so they hire paid posters. As a paid poster, you will register at the forum and post threads and reply to threads, as you normally would do at a forum, and you get paid for each post.
You can contact webmasters and ask them whether they need help boosting their forum, or you can register with a forum boosting company that hires writers and does all the searching work for them. I prefer the latter. Most of these places pay 10-15 cents per post, which I think is acceptable. The work is easy, especially if you get a forum dedicated to a subject you are familiar with. Writing a 15-25 word post will not take long.
I will continue to discuss this money making opportunity in this blog, telling you more about specific paid to post companies and what you need to become a paid poster, so stay tuned. I will post some site link in my next article.
This tools will allow the translation of Google technologies available so that they are in the work flow can be accessed directly from your desktop - without visiting the Google Translator pages via browser. You can translate text, phrase, or paragraph directly or by load file (.txt or .doc). You can translate a website too, just put the website URL and click “Translate”. You can use hotkey for fast access. It can translate various language : English >> German, German >> English, French >> German, German >> French, English >> French, English >> Italian, English >> Portuguese, English >> Spanish, French >> English, Italian >> English, Portuguese >> English, Spanish >> English. Thanks to Smartcoder who has develop this handy tools.
Download Desktop Google Translator from SmartCoder.Net >>

FontStruct is a free font-building (font creator font/designer) that build by famous font retailer FontShop.
Fontstruct equipped with easy to use user interface so you can quickly and easily create fonts constructed out of geometrical shapes, which are arranged in a grid pattern, like tiles or bricks. Be creative and create your own fonts store it to gallery and share it to the others. Once you’re done building, FontStruct generates high-quality TrueType fonts, ready to use in any Mac or Windows application. You can download another user fonts and custom it with your own style and variations.

#include
#define MAX 10
int main()
{
FILE *f;
int x;
f=fopen("out","w");
if (!f)
return 1;
for(x=1; x<=MAX; x++)
fprintf(f,"%d\n",x);
fclose(f);
return 0;
}
The fopen statement here opens a file named out with the w mode. This is a destructive write mode, which means that if out does not exist it is created, but if it does exist it is destroyed and a new file is created in its place. The fopen command returns a pointer to the file, which is stored in the variable f. This variable is used to refer to the file. If the file cannot be opened for some reason, f will contain NULL.
| That is equivalent. However, if (!f) is more common. If there is a file error, we return a 1 from the main function. In UNIX, you can actually test for this value on the command line. See the shell documentation for details. |
The fprintf statement should look very familiar: It is just like printf but uses the file pointer as its first parameter. The fclose statement closes the file when you are done.
The following code demonstrates the process of reading a file and dumping its contents to the screen:
#include
int main()
{
FILE *f;
char s[1000];
f=fopen("infile","r");
if (!f)
return 1;
while (fgets(s,1000,f)!=NULL)
printf("%s",s);
fclose(f);
return 0;
}
The fgets statement returns a NULL value at the end-of-file marker. It reads a line (up to 1,000 characters in this case) and then prints it to stdout. Notice that the printf statement does not include \n in the format string, because fgets adds \n to the end of each line it reads. Thus, you can tell if a line is not complete in the event that it overflows the maximum line length specified in the second parameter to fgets.
|
When you need text I/O in a C program, and you need only one source for input information and one sink for output information, you can rely on stdin (standard in) and stdout (standard out). You can then use input and output redirection at the command line to move different information streams through the program. There are six different I/O commands in
#include
#include
void main()
{
char s[1000];
int count=0;
while (gets(s))
count += strlen(s);
printf("%d\n",count);
}
Enter this code and run it. It waits for input from stdin, so type a few lines. When you are done, press CTRL-D to signal end-of-file (eof). The gets function reads a line until it detects eof, then returns a 0 so that the while loop ends. When you press CTRL-D, you see a count of the number of characters in stdout (the screen). (Use man gets or your compiler's documentation to learn more about the gets function.)
Now, suppose you want to count the characters in a file. If you compiled the program to an executable named xxx, you can type the following:
xxx <>
Instead of accepting input from the keyboard, the contents of the file named filename will be used instead. You can achieve the same result using pipes:
cat <>
You can also redirect the output to a file:
xxx <> out
This command places the character count produced by the program in a text file named out.
Sometimes, you need to use a text file directly. For example, you might need to open a specific file and read from or write to it. You might want to manage several streams of input or output or create a program like a text editor that can save and recall data or configuration files on command. In that case, use the text file functions in stdio:
Okay, before we begin, let me come clean and admit that the title of this article is a little sensationalist! JavaScript doesn’t really have multi-threading capabilities, and there’s nothing a JavaScript programmer can do to change that. In all browsers—apart from Google Chrome—JavaScript runs in a single execution thread, and that’s just how it is.
However, what we can do is simulate multi-threading, insofar that it gives rise to one of the benefits of a multi-threaded environment: it allows us to run extremely intensive code. This is code which would otherwise freeze-up the browser and generate one of those “unresponsive script” warnings in Firefox.
It all hinges on the use of asynchronous timers. When we run repetitive code inside an asynchronous timer, we’re giving the browser’s script interpreter time to process each iteration.
Effectively, a piece of code inside a for iterator is asking the interpreter to do everything straight away: “run this code n times as fast as possible.” However the same code inside an asynchronous timer is breaking the code up into small, discreet chunks; that is, “run this code once as fast possible,”—then wait—then “run this code once as fast as possible”, and so on, n times.
The trick is that the code inside each iteration is small and simple enough for the interpreter to process it completely within the speed of the timer, be it 100 or 5,000 milliseconds. If that requirement is met, then it doesn’t matter how intense the overall code is, because we’re not asking for it to be run all at once.
Normally, if I were writing a script that proved to be too intensive, I would look at re-engineering it; such a significant slowdown usually indicates a problem with the code, or a deeper problem with the design of an application.
But sometimes it doesn’t. Sometimes there’s simply no way to avoid the intensity of a particular operation, short of not doing it in JavaScript at all.
That might be the best solution in a given case; perhaps some processing in an application needs to be moved to the server side, where it has more processing power to work with, generally, and a genuinely threaded execution environment (a web server).
But eventually you may find a situation where that’s just not an option—where JavaScript simply must be able to do something, or be damned. That’s the situation I found myself in when developing my Firefox extension, Dust-Me Selectors.
The core of that extension is the ability to test CSS selectors that apply to a page, to see if they’re actually being used. The essence of this is a set of evaluations using the matchAll() method from Dean Edwards’ base2:
for(var i=0; i
(contentdoc, selectors[i]).length > 0)
{
used ++;
}
else
{
unused ++;
}
}
Straightforward enough, for sure. But matchAll() itself is pretty intense, having—as it does—to parse and evaluate any CSS1 or CSS2 selector, then walk the entire DOM tree looking for matches; and the extension does that for each individual selector, of which there may be several thousand. That process, on the surface so simple, could be so intensive that the whole browser freezes while it’s happening. And this is what we find.
Locking up the browser is obviously not an option, so if this is to work at all, we must find a way of making it run without error.
Let’s demonstrate the problem with a simple test case involving two levels of iteration; the inner level is deliberately too intensive so we can create the race conditions, while the outer level is fairly short so that it simulates the main code. This is what we have:
function process()
{
var above = 0, below = 0;
for(var i=0; i<200000;> 1)
{
above ++;
}
else
{
below ++;
}
}
}
function test1()
{
var result1 = document.getElementById('result1');
var start = new Date().getTime();
for(var i=0; i<200; value =" 'time=" i="'" value =" 'time=">
We kick off our test, and get our output, from a simple form (this is test code, not production, so forgive me for resorting to using inline event handlers):
Now let’s run that code in Firefox (in this case, Firefox 3 on a 2GHz MacBook) … and as expected, the browser UI freezes while it’s running (making it impossible, for example, to press refresh and abandon the process). After about 90 iterations, Firefox produces an “unresponsive script” warning dialog.
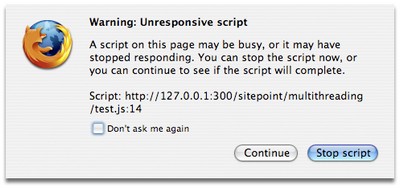
If we allow it to continue, after another 90 iterations Firefox produces the same dialog again.
Safari 3 and Internet Explorer 6 behave similarly in this respect, with a frozen UI and a threshold at which a warning dialog is produced. In Opera there is no such dialog—it just continues to run the code until it’s done—but the browser UI is similarly frozen until the task is complete.
Clearly we can’t run code like that in practice. So let’s re-factor it and use an asynchronous timer for the outer loop:
function test2()
{
var result2 = document.getElementById('result2');
var start = new Date().getTime();
var i = 0, limit = 200, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
result2.value = 'time=' +
(new Date().getTime() - start) + ' [i=' + i + ']';
process();
if(++i == limit)
{
clearInterval(processor);
result2.value = 'time=' +
(new Date().getTime() - start) + ' [done]';
}
busy = false;
}
}, 100);
}
Now let’s run it in again … and this time we receive completely different results. The code takes a while to complete, sure, but it runs successfully all the way to the end, without the UI freezing and without warnings about excessively slow scripting.
(The busy flag is used to prevent timer instances from colliding. If we’re already in the middle of a sub-process when the next iteration comes around, we simply just wait for the following iteration, thereby ensuring that only one sub-process is running at a time.)
So you see, although the work we can do on the inner process is still minimal, the number of times we can run that process is now unlimited: we can run the outer loop basically forever, and the browser will never freeze.
That’s much more like it—we can use this in the wild.
I can hear the objectors already. In fact, I could be one myself: why would you do this—what kind of crazy person insists on pushing JavaScript to all these places it was never designed to go? Your code is just too intense. This is the wrong tool for the job. If you have to jump through these kinds of hoops then the design of your application is fundamentally wrong.
I’ve already mentioned one example where I had to find a way for heavy scripting to work; it was either that, or the whole idea had to be abandoned. If you’re not convinced by that answer, then the rest of the article may not appeal to you either.
But if you are—or at least, if you’re open to being convinced, here’s another example that really nails it home: using JavaScript to write games where you can play against the computer.(coming soon)



